[1]:
import sys
import rics
# Print relevant versions
print(f"{rics.__version__=}")
print(f"{sys.version=}")
!git log --pretty=oneline --abbrev-commit -1
rics.__version__='0.17.0.dev1'
sys.version='3.10.6 (main, Aug 10 2022, 11:40:04) [GCC 11.3.0]'
10ec07f (HEAD, origin/main, origin/HEAD, main) formatting
[2]:
import logging
rics.configure_stuff(level=logging.INFO, rics_level=logging.DEBUG)
In vs between (legacy)#
What’s faster at various counts of requests IDs?
[3]:
import sqlalchemy
engine = sqlalchemy.create_engine("postgresql+pg8000://postgres:your_password@localhost:5432/imdb")
Define candidates#
Define the functions or classes we’re testing. See candidates.py for the actual file, or the end of this notebook for a printout.
[4]:
# candidates.py is located in the same folder as this notebook
from candidates import Candidates
c = Candidates(engine)
candidates = [c.as_is, c.between, c.is_in, c.heuristic]
Verification#
Make sure candidates are equivalent.
[5]:
import numpy as np
all_ids = [int(row[0]) for row in c.as_is([])]
int_list = lambda size: list(map(int, np.random.choice(all_ids, size=size, replace=False)))
test_data = {f"{size} ids": int_list(size) for size in [50, 250, 500, 1000, 2500, 5000, 10_000]}
[6]:
first_case = next(iter(test_data.keys()))
must_include = set(test_data[first_case])
for cand in candidates:
cand_output = set(row[0] for row in cand(test_data[first_case]))
assert not must_include.difference(cand_output), f"Bad candidate: {cand}. {cand_output=} != {reference_output=}"
Run performance comparison#
Run comparison, show results per candidate and test data set. Click here for docs.
[7]:
from rics.performance import run_multivariate_test, get_best
data = run_multivariate_test(candidates, test_data, time_per_candidate=90)
2022-10-05T20:11:46.496 [rics.performance:INFO] Evaluate candidate 'as_is' 5x12 times..
2022-10-05T20:13:12.405 [rics.performance:INFO] Evaluate candidate 'between' 5x12 times..
2022-10-05T20:14:35.859 [rics.performance:INFO] Evaluate candidate 'is_in' 5x46 times..
2022-10-05T20:15:55.275 [rics.performance:INFO] Evaluate candidate 'heuristic' 5x28 times..
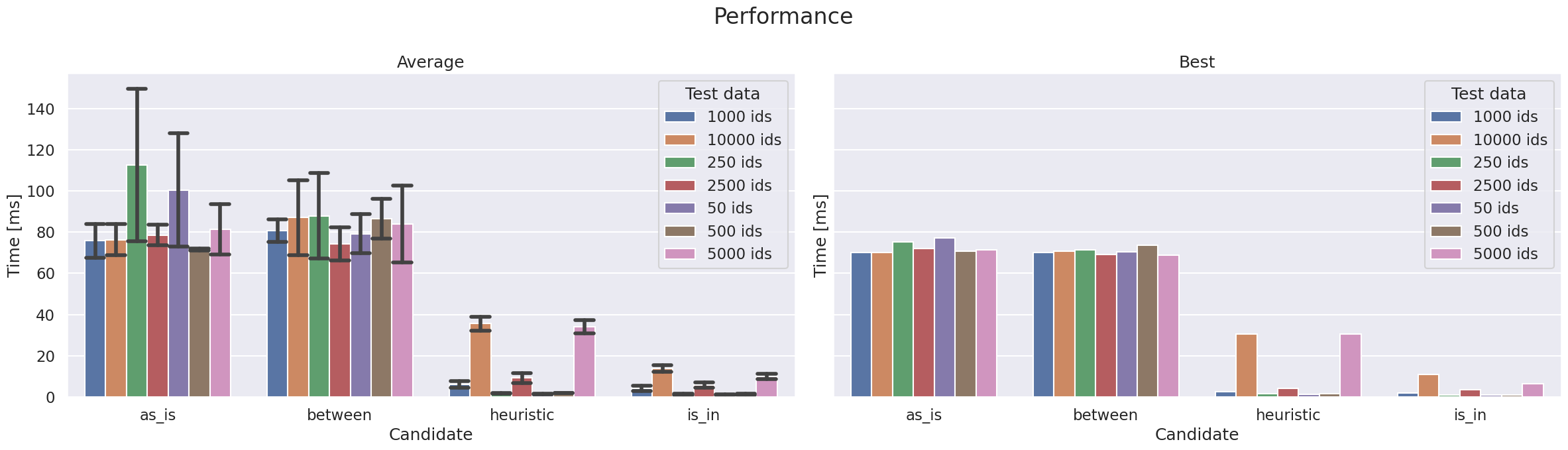
Performance summary#
Summarized results per candidate.
[8]:
get_best(data)
[8]:
| Time [s] | Time [ms] | Time [μs] | ||
|---|---|---|---|---|
| Candidate | Test data | |||
| as_is | 1000 ids | 0.0702218 | 70.2218 | 70221.8 |
| 10000 ids | 0.0700298 | 70.0298 | 70029.8 | |
| 250 ids | 0.0753974 | 75.3974 | 75397.4 | |
| 2500 ids | 0.0721644 | 72.1644 | 72164.4 | |
| 50 ids | 0.077134 | 77.134 | 77134 | |
| 500 ids | 0.0705988 | 70.5988 | 70598.8 | |
| 5000 ids | 0.0713147 | 71.3147 | 71314.7 | |
| between | 1000 ids | 0.0700795 | 70.0795 | 70079.5 |
| 10000 ids | 0.0707501 | 70.7501 | 70750.1 | |
| 250 ids | 0.0712644 | 71.2644 | 71264.4 | |
| 2500 ids | 0.069016 | 69.016 | 69016 | |
| 50 ids | 0.0704004 | 70.4004 | 70400.4 | |
| 500 ids | 0.0735775 | 73.5775 | 73577.5 | |
| 5000 ids | 0.0688786 | 68.8786 | 68878.6 | |
| heuristic | 1000 ids | 0.00254428 | 2.54428 | 2544.28 |
| 10000 ids | 0.0305486 | 30.5486 | 30548.6 | |
| 250 ids | 0.00154327 | 1.54327 | 1543.27 | |
| 2500 ids | 0.0041925 | 4.1925 | 4192.5 | |
| 50 ids | 0.00139524 | 1.39524 | 1395.24 | |
| 500 ids | 0.00177693 | 1.77693 | 1776.93 | |
| 5000 ids | 0.0304048 | 30.4048 | 30404.8 | |
| is_in | 1000 ids | 0.00206929 | 2.06929 | 2069.29 |
| 10000 ids | 0.0110818 | 11.0818 | 11081.8 | |
| 250 ids | 0.00102729 | 1.02729 | 1027.29 | |
| 2500 ids | 0.00351571 | 3.51571 | 3515.71 | |
| 50 ids | 0.000898022 | 0.898022 | 898.022 | |
| 500 ids | 0.00112437 | 1.12437 | 1124.37 | |
| 5000 ids | 0.00633283 | 6.33283 | 6332.83 |
Conclusion#
Probably unfair in favour of fetching “too much” since the DB is running locally. We’re also fetching the same things over and over again which may lead to caching.
The heuristic method seems good and will only get better with tuning.
IDs in this data set (
title_basics) are very sparse which causes poor performance for the heuristic on the “5000 ids” set; performance drops earlier than for pureas_in.Heuristic method is suscptible to sparse ID collections
Results for
is_inare not cached, it just performs poorly for large amounts of “in”-values.
Use heuristic method.
Show candidates.py#
[9]:
!pygmentize candidates.py
import sqlalchemy
# This value is probably a bit off compared to other real-world scenarios since IDs are very sparse in the IMDb data
MAX_OVERFETCH_FACTOR = 50
class Candidates:
def __init__(self, engine):
self.engine = engine
metadata = sqlalchemy.MetaData()
metadata.reflect(engine)
self.id_column = metadata.tables["title_basics"].columns["int_id_tconst"]
extra_cols = (
metadata.tables["title_basics"].columns["primaryTitle"],
metadata.tables["title_basics"].columns["originalTitle"],
metadata.tables["title_basics"].columns["runtimeMinutes"],
)
self.bare_select = sqlalchemy.select(self.id_column, *extra_cols)
def _exec(self, stmt):
return list(self.engine.execute(stmt))
def as_is(self, ids):
return self._exec(self.bare_select)
def between(self, ids):
min_id = min(ids)
max_id = max(ids)
select = self.bare_select.where(self.id_column.between(min_id, max_id))
return self._exec(select)
def is_in(self, ids):
return self._exec(self.bare_select.where(self.id_column.in_(ids)))
def heuristic(self, ids):
stmt = self.bare_select
num_ids = len(ids)
in_clause = stmt.where(self.id_column.in_(ids))
if num_ids < 1200:
return self._exec(in_clause)
min_id = min(ids)
max_id = max(ids)
between_clause = stmt.where(self.id_column.between(min_id, max_id))
if num_ids > 4500:
return self._exec(between_clause)
overfetch_factor = (max_id - min_id) / num_ids
return self._exec(in_clause if overfetch_factor > MAX_OVERFETCH_FACTOR else between_clause)
[ ]: