[1]:
import sys
import rics
# Print relevant versions
print(f"{rics.__version__=}")
print(f"{sys.version=}")
!git log --pretty=oneline --abbrev-commit -1
rics.__version__='0.1.0'
sys.version='3.8.10 (default, Nov 26 2021, 20:14:08) \n[GCC 9.3.0]'
0eec68c (HEAD -> sql-id-select) SQL Fetcher: Fix column selection
[2]:
from rics.utility.logs import basic_config, logging
basic_config(level=logging.DEBUG, matplotlib_level=logging.INFO)
In vs between#
What’s faster at various counts of requests IDs?
[3]:
import sqlalchemy
engine = sqlalchemy.create_engine("postgresql://postgres:your_password@localhost:5432/imdb")
Define candidates#
Define the functions or classes we’re testing. See candidates.py.
[4]:
# candidates.py is located in the same folder as this notebook
from candidates import Candidates
c = Candidates(engine)
Candidates#
def as_is(self, ids):
return list(self.engine.execute(self.bare_select))
def between(self, ids):
min_id, max_id = min(ids), max(ids)
select = self.bare_select.where(self.id_column.between(min_id, max_id))
return list(self.engine.execute(select))
def is_in(self, ids):
return list(self.engine.execute(self.bare_select.where(self.id_column.in_(ids))))
def heuristic(self, ids):
"""Switch between the others based on number of IDs."""
[5]:
candidates = [c.as_is, c.between, c.is_in, c.heuristic]
Verification#
Make sure candidates are equivalent.
[6]:
import numpy as np
all_ids = [int(row[0]) for row in c.as_is([])]
int_list = lambda size: list(map(int, np.random.choice(all_ids, size=size, replace=False)))
test_data = {f"{size} ids": int_list(size) for size in [50, 250, 500, 1000, 2500, 5000, 10_000]}
[7]:
first_case = next(iter(test_data.keys()))
must_include = set(test_data[first_case])
for cand in candidates:
cand_output = set(row[0] for row in cand(test_data[first_case]))
assert not must_include.difference(cand_output), f"Bad candidate: {cand}. {cand_output=} != {reference_output=}"
Run perfomance comparison#
Run comparison, show results per candidate and test data set.
[8]:
from rics.utility.perf import run_multivariate_test, format_perf_counter
import seaborn as sns
import matplotlib.pyplot as plt
sns.set_theme("notebook")
fig, ax = plt.subplots(figsize=(15, 4))
ax.set_title("Performance comparison")
data = run_multivariate_test(candidates, test_data, time_per_candidate=30, ax=ax)
plt.legend(loc="lower left")
2022-03-14T10:11:47.453 [rics.utility.perf:INFO] Expected total runtime: 0:10:00.
2022-03-14T10:11:47.455 [rics.utility.perf:DEBUG] Run candidate 'as_is' 5x75 times...
2022-03-14T10:14:23.387 [rics.utility.perf:DEBUG] Run candidate 'between' 5x64 times...
2022-03-14T10:16:40.597 [rics.utility.perf:DEBUG] Run candidate 'is_in' 5x194 times...
2022-03-14T10:19:06.949 [rics.utility.perf:DEBUG] Run candidate 'heuristic' 5x168 times...
[8]:
<matplotlib.legend.Legend at 0x7fcb05057130>
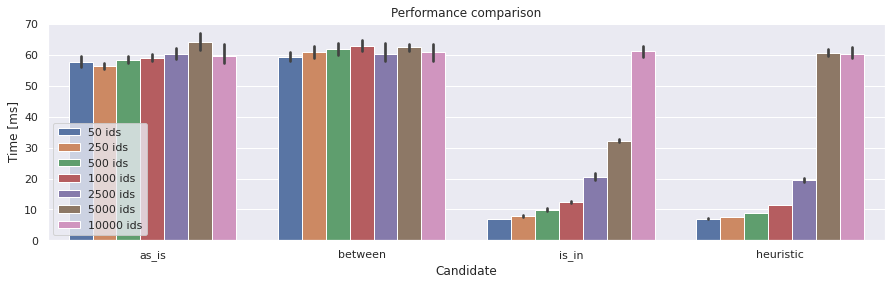
Performance summary#
Summarized results per candidate.
[9]:
data.groupby("Candidate")["Time [ms]"].agg(["std", "mean", "min", "max"]).sort_values("mean").round(1)
[9]:
| std | mean | min | max | |
|---|---|---|---|---|
| Candidate | ||||
| is_in | 18.4 | 21.6 | 6.9 | 63.5 |
| heuristic | 23.1 | 25.1 | 7.0 | 64.4 |
| as_is | 3.3 | 59.4 | 54.5 | 69.2 |
| between | 2.7 | 61.3 | 56.1 | 66.6 |
Conclusion#
Probaby unfair in favour of fetching “too much” since the DB is running locally. We’re also fetching the same things over and over again which may lead to caching.
The heuristic method seems good and will only get better with tuning.
IDs in this data set (
title_basics) are very sparse which causes poor performance for the heuristic on the “5000 ids” set; performance drops earlier than for pureas_in.Heuristic method is suscptible to sparse ID collections
Results for
is_inare not cached, it just performs horrendously bad for large amounts of “in”-values.
Use heuristic method.
[ ]: